
Data-Compost
Futur antérieur, tentative de compostage de données numériques, 2025Travail de recherche mené avec le soutien du CNAP Centre national des arts plastiques, 2025
L’histoire du stockage de l’information reflète l’évolution de notre civilisation. Des hiéroglyphes gravés dans la pierre aux technologies quantiques émergentes, notre quête de préservation de la mémoire collective n’a cessé de se transformer et de s’adapter aux défis de chaque époque. Dès la préhistoire, l’humanité a cherché à consigner son savoir à travers les pétroglyphes et les hiéroglyphes. Ce n’est qu’avec l’avènement de l’informatique dans les années 1940 que commence véritablement l’ère du stockage de données numériques. Des cartes perforées aux clouds actuels, l’évolution des supports de stockage témoigne d’une course constante vers plus de données dans moins d’espace et pour plus longtemps.
Une « ruée vers l’or » où l’accumulation des données est de mise au détriment de la transformation
La gestion des données est aujourd’hui largement contrôlée par des entreprises privées qui ont intérêt à encourager l’accumulation plutôt que la transformation. Les géants de la tech ont intérêt à accumuler des données, car cela alimente leurs modèles économiques basés sur la publicité ciblée, les services personnalisés et le développement de technologies d’IA. Les modèles d’IA, en particulier les modèles de langage ou les générateurs d’images, nécessitent d’énormes quantités de données pour leur entraînement. Par exemple, ChatGPT a été entraîné sur environ 570 Go de textes, soit environ 300 milliards de mots. De même, le modèle Stable Diffusion a utilisé un ensemble de données contenant 5,8 milliards de paires image-texte.
Le paradoxe est que le flux de génération d’images et textes par les LLM (large language model) pourrait perturber les futures modèles car nous n’aurons bientôt plus assez de données pertinentes pour entraîner des IA. Il s’agit du phénomène de « model collapse » décrit dans une étude de 2023 intitulée The Curse of Recursion: Training on Generated Data Makes Models Forget, qui démontre que l’entraînement de modèles sur des données synthétiques peut générer une perte irréversible d’information. Une autre étude de 2024, Theoretical Proof that Generated Text in the Corpus Leads to the Collapse of Auto-regressive Language Models, fournit une preuve théorique que l’entraînement répété sur des textes générés par l’IA conduit inévitablement à un effondrement du modèle. Enfin le groupe de chercheur Epoch AI prédit un épuisement des données disponibles pour entraîner des modèles d’IA entre 2026 et 2032.
En proposant une alternative basée sur des principes écologiques, il s’agit d’ouvrir un espace de réflexion critique sur les modèles économiques du numérique et leurs implications environnementales. Est-il important de conserver 18 millions de vidéos de chat à l’heure de la sixième extinction ? Viendra peut-être un jour où les vidéos de chats remplaceront les chats.
La croissance rapide des données numériques a un impact considérable sur notre environnement
Apparu dans les années 1990, le terme « Big Data » marque un tournant décisif. Les volumes de données croissent de manière exponentielle, passant de 33 zettaoctets en 2018 à une projection de 175 zettaoctets en 2025. Cette croissance vertigineuse pose de nouveaux défis en termes de stockage et de gestion durable des données. Les technologies du cloud transforme le problème en créant une sorte de Pièce en plus infinie dans laquelle on entasse des données.
L’expansion rapide des données numériques a des conséquences environnementales significatives qu’il est crucial de considérer. Avec la croissance constante du besoin de stockage, de traitement et de transmission de données, l’énergie nécessaire pour réaliser ces opérations s’accroît de manière proportionnelle. Cela entraîne une augmentation des émissions de gaz à effet de serre, un épuisement des ressources naturelles et une pollution due aux méthodes de production d’énergie, qui contribuent à la dégradation des écosystèmes et de la santé publique.
Les centres de données, qui comptent parmi les consommateurs d’électricité dont la croissance est la plus rapide, représentent environ 1,1 à 1,5 % de la demande mondiale d’électricité et contribuent entre 2,5 à 3,7 % de toutes les émissions de gaz à effet de serre. La construction et l’exploitation de ces installations aggravent la situation, car elles consomment de grandes quantités d’énergie, souvent provenant de combustibles fossiles, sapant ainsi les efforts visant à atteindre les objectifs de neutralité carbone.
Viendra peut-être un jour où <b>les vidéos de chats remplaceront les chats.</b>
Cette recherche d’alternatives écologiques trouve un écho particulier dans le mouvement émergent du permacomputing, qui transpose les principes de la permaculture au domaine numérique. Né au début des années 2020 le permacomputing prône une approche radicalement différente de la technologie : maximiser la durée de vie du matériel, minimiser la consommation d’énergie, et considérer les contraintes non pas comme des limitations mais comme des catalyseurs de créativité. Contrairement à l’esthétique dominante qui glorifie toujours plus de pixels, plus de puissance et plus de données, le permacomputing célèbre la possibilité d’être créatif avec des ressources limitées. Cette philosophie résonne profondément avec l’approche Data-Compost : là où le permacomputing questionne nos pratiques de consommation technologique, le compostage numérique propose des méthodes concrètes de transformation des données existantes. Les deux approches partagent cette vision biomimétique où les contraintes écologiques deviennent des forces créatrices plutôt que des obstacles à contourner.
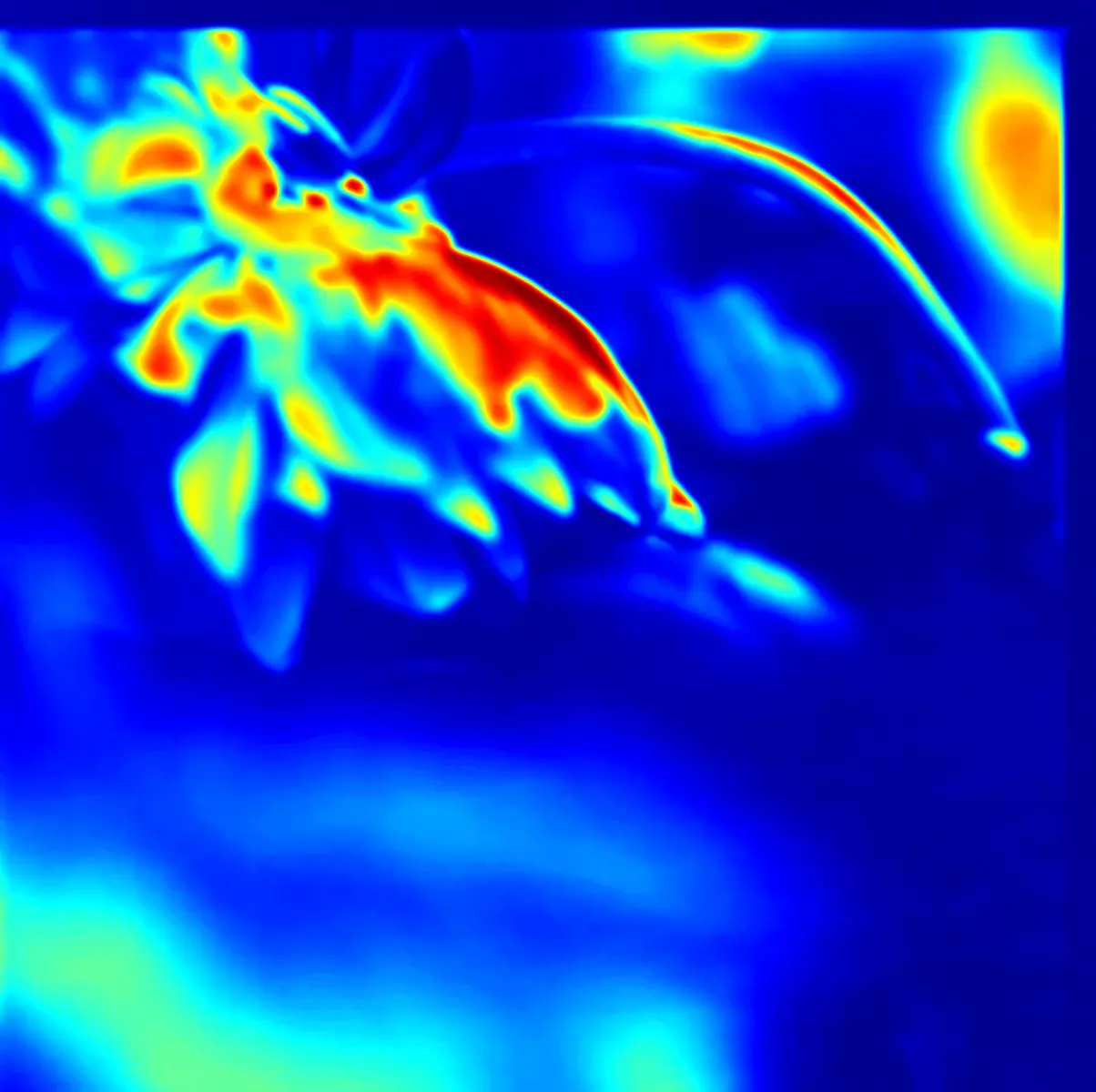
Certains points soulèvent des questions fondamentales, bien souvent ignorées, comme les saliency map ou cartes de saillance qui déterminent de manière automatique les points d’intérêt des images ou des vidéos, provoquant indubitablement la mécanisation de nos critères esthétiques et incarnent une forme de pouvoir qui mérite d’être questionnée. Qui écrit ces algorithmes ? Qui définit ces critères ? Comment ces choix techniques influencent-ils notre perception du monde ?
Contrecarrer l’impact environnemental des appareils électroniques et des données numériques
Eliminer et/ou recycler les vieux appareils
Il va de soi que le cycle de vie du hardware, de sa conception à son recyclage, contribue de manière significative à la dégradation des écosystèmes, en cause l’extraction de terres rares qui ne se fait pas dans les meilleures conditions, mais aussi les déchets électroniques, qu’il est très couteux de recycler proprement ; de plus ils contiennent des matières dangereuses qui peuvent nuire à la qualité du sol, de l’eau et de l’air. Plus le nombre d’usagers du numérique augmentent et plus la technologie évolue, plus le problème des déchets électroniques devient critique. Évidemment il s’agit là d’un problème majeur qu’il est difficile de prendre en charge sans penser globalement des stratégies efficaces de gestion des déchets électroniques comprenant l’établissement de programmes de collecte, la construction d’installations de recyclage et la mise en œuvre de cadres réglementaires pour garantir une gestion appropriée des appareils mis au rebut.
Réduire la consommation d’énergie
Pour réduire l’impact environnemental des données numériques, l’accent est de plus en plus mis sur les solutions informatiques durables, les technologies vertes. Les géants de la tech, avant l’explosion de l’usage des IA génératives, misaient sur une neutralité carbone à l’horizon 2030. En promouvant des innovations visant à réduire la consommation d’énergie, en équipant leurs centres de données de sources d’énergies renouvelables ou en investissant dans des solutions naturelles ou technologiques pour capter le carbone, ils parviendraient à atteindre leurs objectifs zéro émission. À l’échelle individuelle, il est évidemment possible de limiter, voire de réduire, notre empreinte carbone liée à nos usages du numérique, encore faut-il avoir conscience de notre consommation réelle. Aujourdhui la plupart des services que nous utilisons se servent de l’IA sans que nous le sachions.
Repenser la gestion des données
La gestion des données numériques joue un rôle crucial dans la réduction de l’empreinte carbone. Les organisations sont encouragées à adopter des stratégies de minimisation des données en auditant et en supprimant régulièrement les données inutiles. En ne conservant que les informations essentielles, les entreprises peuvent réduire les besoins de stockage des centres de données, ce qui entraîne une réduction de la consommation d’énergie et de l’impact environnemental. Cette pratique soutient non seulement la durabilité, mais s’aligne également sur les objectifs plus larges de la pensée circulaire, où les ressources sont continuellement réutilisées et les déchets sont minimisés. À notre échelle, il est évident que nous pouvons limiter la quantité de données numériques présentes sur les serveurs, et les stocker localement, etc. Le designer graphique peut aussi par sa pratique proposer des sites à faible empreinte carbone. Tous ces gestes et toutes ces bonnes pratiques sont largement documentées par The Shift Project, Gauthier Roussilhe et le projet de recherche « limites numériques ».
Alors que le stockage et le traitement des données consomment une part croissante des ressources énergétiques mondiales, Data-Compost propose une approche qui pourrait réduire cette empreinte écologique. En acceptant la transformation et la perte des données comme parties intégrantes du processus de conservation, le projet suggère d’autres modes de gestion des ressources numériques. Data-Compost explore cette question en expérimentant des algorithmes qui simulent le vieillissement et la décomposition des données, il crée ainsi une nouvelle forme d’esthétique numérique basée sur la transformation plutôt que sur la préservation.
En transposant les principes du compostage biologique le compostage numérique ouvre une nouvelle voie.
La méthodologie du projet Data-Compost s’inspire de la méthode de compostage de Berkeley, reconnue pour son efficacité dans le domaine biologique. Cependant, plutôt qu’une simple transposition, il suggère d’adapter créativement ces principes actifs au contexte numérique. Cette adaptation nécessite une compréhension fine des spécificités du medium numérique, notamment son caractère binaire et sa capacité à être cloné parfaitement.
L’adaptation des principes de la méthode de Berkeley au contexte numérique représente un défi conceptuel majeur. Comment transposer des notions comme la température, l’humidité ou l’aération dans le domaine binaire des données numériques ? Le projet propose des équivalents, créant ainsi un nouveau vocabulaire pour penser la transformation des données. Cette traduction conceptuelle ouvre des perspectives pour repenser notre rapport au numérique. L’un des défis majeurs concerne la métaphore entre compostage physique et compostage numérique, qu’est-ce qu’une matière « grise » et qu’est-ce qu’une matière « verte » dans le monde numérique, comment déterminer le taux de carbone et d’azote d’un fichier numérique et donc son rapport carbone / azote mais plus généralement quelle serait la définition même de la « mort numérique ». Contrairement aux matières organiques, les données numériques ne se dégradent pas naturellement.
Le projet Data-Compost propose donc une réflexion sur la création de mécanismes de dégradation artificielle qui respectent l’essence même du medium numérique tout en s’inspirant des processus naturels. Tout comme le compost biologique enrichit le sol pour de futures cultures, le compostage numérique vise à créer un substrat fertile pour de nouvelles créations humaines, transformant ainsi nos rebuts numériques en matières inspirantes et pourquoi pas lutter contre le phénomène du « model collapse ».
En proposant une nouvelle approche de la gestion des données, Data-Compost questionne nos pratiques individuelles et collectives de conservation numérique. Comment une société peut-elle gérer durablement sa mémoire numérique ? Quels rituels de transformation et de deuil pouvons-nous développer pour nos données ?
Le projet Data-Compost invite à repenser notre rapport aux données
Le projet s’inscrit dans une réflexion plus large sur le numérique à l’ère de l’Anthropocène. À l’heure où l’impact environnemental du numérique devient préoccupant, Data-Compost propose une voie alternative en tentant de réconcilier innovation technologique et conscience écologique. Cette approche suggère que la solution aux défis environnementaux du numérique ne réside pas uniquement dans l’optimisation technique, mais aussi dans un changement profond de paradigme. En termes de potentiel transformatif, le projet ouvre des perspectives pour repenser l’archivage numérique. Plutôt qu’une accumulation passive de données, il propose un modèle dynamique où la conservation devient un processus actif de transformation et de régénération.
Data-Compost contribue à développer une pensée du numérique moins binaire et plus sophistiquée en désinvisilibilisant ce qui se joue derrière la conservation d’une donnée, d’un mail, d’un bit. Cette approche aide à comprendre que nos actions numériques ont des conséquences matérielles et environnementales réelles, encourageant ainsi une utilisation plus responsable des technologies. Ceci soulève également des questions importantes sur la matérialité du numérique. En établissant un parallèle avec les processus biologiques, il nous rappelle que le monde numérique, malgré son apparente immatérialité, repose sur des infrastructures physiques qui ont un impact environnemental concret. Cette prise de conscience est essentielle pour développer une approche plus durable du numérique.
L’un des thèmes qui est partiellement abordé ici, mais qu’il faudra développer, concerne une réflexion sur la temporalité numérique. Contrairement à la vision dominante qui considère les données numériques comme immuables et éternelles, Data-Compost introduit la notion de dégradation contrôlée comme processus créatif. Cette approche s’inspire notamment des travaux sur la mémoire humaine, où l’oubli sélectif joue un rôle aussi important que la conservation, dans la construction du sens. Il soulève également des questions éthiques fondamentales sur notre responsabilité envers l’héritage numérique que nous léguons aux générations futures. Dans un contexte où l’accumulation de données devient insoutenable tant écologiquement que culturellement, comment définir une éthique de la conservation numérique ? Quels critères utiliser pour décider ce qui mérite d’être préservé, transformé ou laissé à la «décomposition» ?
Rendre tangibles et visibles des concepts abstraits
La dimension artistique du projet joue un rôle crucial dans sa capacité à toucher un public large. Les œuvres générées par le processus de compostage numérique ne sont pas de simples visualisations de données, mais des explorations actives de la frontière entre conservation et transformation. Cette approche artistique permet de rendre tangibles des concepts abstraits et de susciter une réflexion émotionnelle sur notre rapport aux données.
Il est important de souligner l’aspect ritualisé qui pourrait émerger du compostage numérique. Dans un monde où la suppression de données est souvent vécue comme une perte traumatique, le projet propose des rituels de transformation qui donnent sens à ce processus. Ces rituels numériques permettent d’accompagner la transformation des données d’une manière qui respecte leur importance tout en acceptant leur caractère transitoire.
La visée pédagogique du projet ne se limite pas à conscientiser les citoyens aux enjeux environnementaux du numérique. En rendant lisible et intelligible le fait que nos téléchargements, mails, recherches (et bien d’autres) requièrent de l’énergie et ont un impact sur nos écosystème, Data-Compost participe à visibiliser ce qui reste encore caché derrière des concepts marketing comme le « Cloud ». Ce qui permettra à chacun de comprendre que, s’ils sont invisibles et immatériels, nos usages quotidiens du numériques, sont eux réels, matériels et bien souvent polluants et consommateurs de ressources d’énergie non renouvelables.
Le projet soulève également des questions importantes sur l’archivage institutionnel. Comment les bibliothèques, les musées et autres institutions culturelles peuvent-ils intégrer ces principes de transformation dans leurs pratiques de conservation ? Le projet suggère que l’archivage numérique pourrait devenir un processus plus dynamique, où la conservation ne signifie pas nécessairement la préservation à l’identique. En proposant une alternative à la logique d’accumulation, Data-Compost pourrait expérimenter de nouvelles façons pour les organisations de gérer leurs données. Cette approche pourrait ouvrir des discussions sur de nouvelles méthodes pour évaluer la « valeur » des données qui prennent en compte leur potentiel de transformation plutôt que leur utilité immédiate.
En conclusion, Data-Compost tente d’expérimenter des alternatives durables dans le domaine numérique. En combinant rigueur conceptuelle, sensibilité artistique et conscience écologique, le projet propose une vision renouvelée de notre relation aux données numériques. Cette approche biomimétique ouvre la voie à de nouvelles façons de penser et de mettre en pratique une « écologie numérique », tout en contribuant à une réflexion plus large sur l’avenir de notre société technologique.





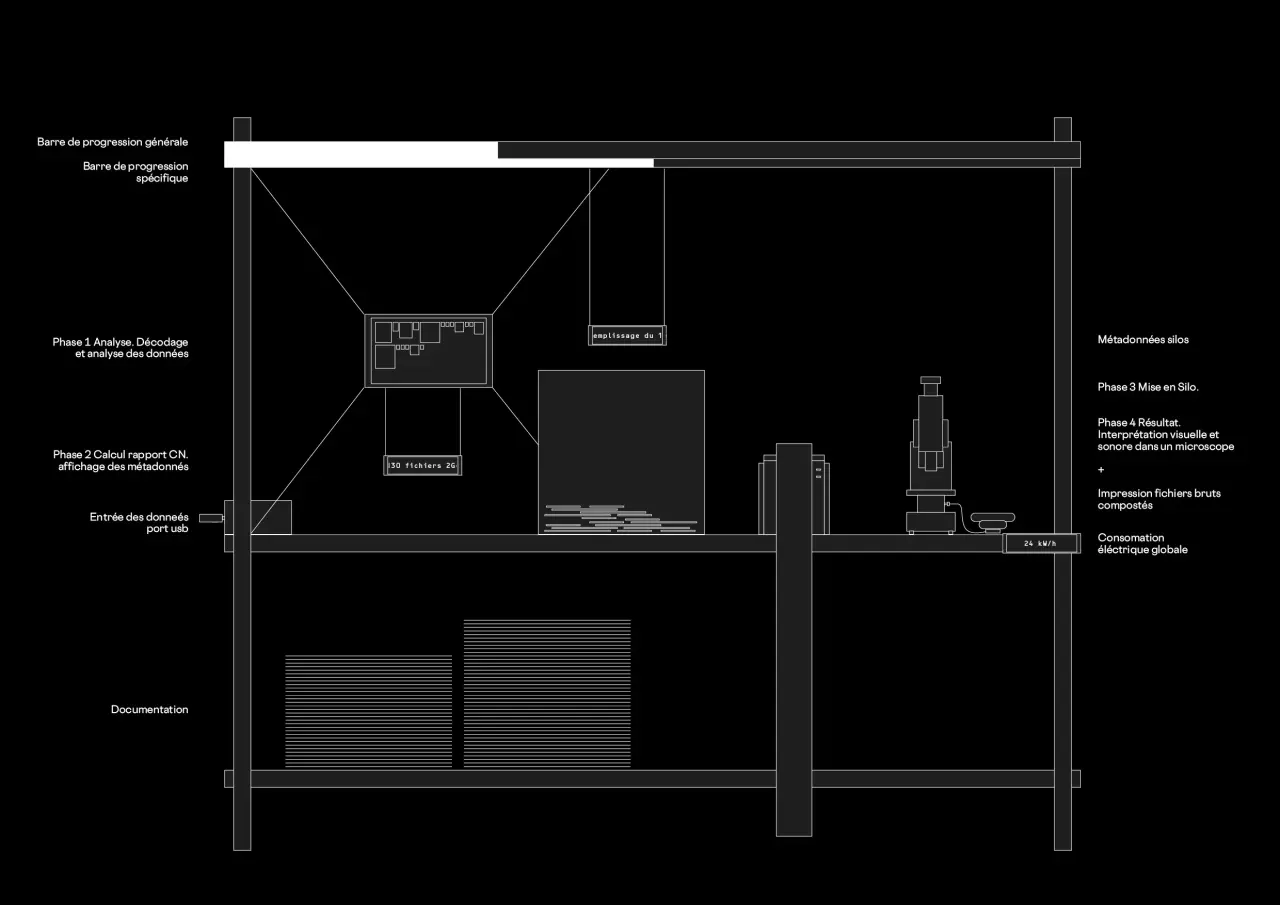
Premières expériences
sur tout type de fichiers
Les premiers tests réalisés ont pris en compte tous types de fichiers (fichiers cachés, exécutables, images, vidéos, audios, documents textes, tableaux, etc.), abordant ainsi le problème dans sa globalité. Le processus algorithmique reprend les grands principes du compostage de Berkeley en s’adaptant au monde numérique. Les différents scripts créés mettent en scène une analyse poussée des fichiers, une estimation de la teneur en carbone et en azote, une classification des fichiers en matière «brune» et matière « verte », un calcul du rapport carbone/azote, la mise en silo en optimisant pour chaque silo le rapport carbone/azote, la décomposition des fichiers à l’intérieur de chaque silo, le renversement des silos, la décomposition et le mélange des données dans chaque silo, puis le mélange de toutes les données compostées. Le résultat final est un fichier binaire brut que nous pouvons interpréter de différentes manières. Après plusieurs tentatives, le choix a été fait de tirer ces expériences vers la sensibilisation et la pédagogie en imaginant une installation numérique qui exige la participation du spectateur. Cette installation retrace les différentes étapes du compostage numérique : l’utilisateur vient avec des données à composter, il met sa clé USB, le système démarre et montre les différentes étapes, jusqu’au résultat final qui est imprimé sur une imprimante thermique et interprété visuellement et sonifié. Le tout est piloté par un Raspberry Pi 5 et utilise trois écrans différents et une imprimante thermique. L’écran circulaire LCD 4 inch connecté en DSI est alimenté grâce au GPIO, il affiche la phase actuelle, la progression et le résultat final. L’écran LCD 7 inch connecté en HDMI montre les visualisations détaillées du processus, l’écran e-paper 2.9 inch connecté en GPIO, présente les statistiques et informations clés et l’imprimante thermique Epson TM T70II connectée en USB et imprime le fichier binaire brut.

Tentatives de création d’algorithmes
plus spécifiques à la décomposition des fichiers images
Les tentatives de décomposition de fichiers images sont postérieures aux autres tentatives, elles répondent à la volonté de travailler l’image ; une sorte de déformation professionnelle ou une légère frustration ressentie face aux précédents résultats. Ainsi, j’essaye dans un premier temps de recenser toutes les méthodes de décomposition des images et je m’intéresse particulièrement aux trames, à la pixellisation, au data-moshing et au pixel-sorting. Je fais plusieurs tentatives et je crée plusieurs interfaces pour contrôler au mieux la dégradation. Je tente d’appliquer ces différents modules de dégradation selon plusieurs méthodes : selon la taille du fichier, selon le temps, selon la description qui peut en être tirée, selon les couleurs principales ou encore selon la carte de saillance. J’essaye de combiner les méthodes de décomposition en fonction de la carte de saillance. Les résultats commencent à être intéressants.
Les visuels qui suivent ont été générés à partir de photographies non sélectionnées de prises de vue de Thérèse Verrat et Vincent Toussaint.
Processus 001
voir toutes les images

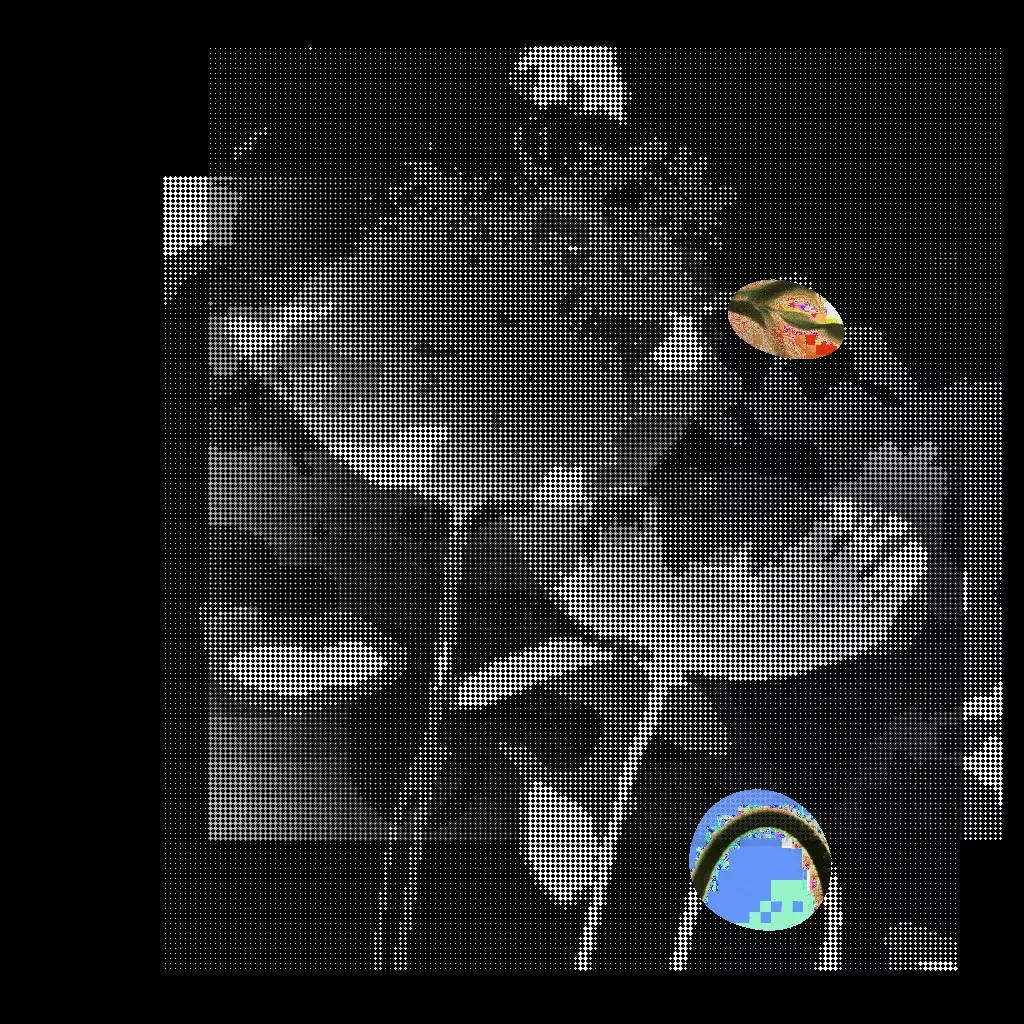

Processus 002
voir toutes les images



Processus 003
voir toutes les images



Le projet Futur antérieur. Compostage numérique, a été soutenu par le Cnap, centre national des arts plastiques